
Synthetic and federated: Privacy-preserving domain adaptation with LLMs for mobile applications
July 24, 2025
Zheng Xu, Research Scientist, and Yanxiang Zhang, Software Engineer, Google
Privacy-preserving synthetic data in federated learning can improve both small and large language models, with practical applications in Gboard to improve users' typing experience.
The recent success of machine learning models relies on not only large-scale, but also high-quality data. The paradigm of pre-training on massive data collected on the web and post-training on smaller high-quality data is used to train both large and small language models (LMs). For large models, post-training has proven vital for aligning models to user intent, and post-training of small models to adapt to the user domain has yielded significant results, for example, achieving 3%–13% improvements in key production metrics for mobile typing applications.
However, in complex LM training systems, there are potential privacy risks, such as the memorization of sensitive user instruction data. Privacy-preserving synthetic data provides one path to access user interaction data to improve models while systematically minimizing privacy risks. With the generation capabilities of large LMs (LLMs), synthetic data can be created to mimic user data without risk of memorization. This synthetic data can then be used in model training just as public data is used, simplifying privacy-preserving model training.
Gboard uses both small LMs and LLMs to improve billions of users’ typing experience. Small LMs support core features like slide to type, next word prediction (NWP), smart compose, smart completion and suggestion; LLMs support advanced features like proofread. In this blog post, we share our exploration over the past few years on generating and using synthetic data to improve LMs for mobile typing applications. We focus on approaches adhering to the privacy principles of both data minimization and data anonymization, and show how they are making a real-world impact in small and large models in Gboard. Particularly, our recent paper, “Synthesizing and Adapting Error Correction Data for Mobile Large Language Model Applications”, discusses the advances in privacy-preserving synthetic data for LLMs in production, building upon our continuous research efforts discussed below [1, 2, 3, 4, 5].
Gboard completion, correction, and prediction features powered by small decoder LMs, and the advanced proofreading feature for error correction powered by LLMs.
Learning from public and private data in practice
Our 2024 blog discussed the best practices of privacy-preserving training on user data to adapt small LMs to the domain of mobile typing text. Federated learning (FL) with differential privacy (DP) is applied so that user data stored on one’s own device has only minimum exposure (i.e., restrictive access control) during training, and is not memorized by the trained models. Pre-training on web data improves the performance of private post-training, empowering the deployment of user-level DP in production. For the purposes of today’s blog, we consider user data generated in applications as private data, and accessible web data and models trained on them as public information (where we apply a privacy defense-in-depth strategy to mitigate concerns on potential information leakage in public data).
Today, all Gboard production LMs trained on user data use FL with DP guarantees, including key decoder models and the 2024 NWP models. This milestone is achieved by launching dozens of new LMs trained with federated learning and differential privacy (DP-FL LMs), and replacing all older FL-only models. Research advances have continued rapidly since 2024: we employ a new DP algorithm, BLT-DP-FTRL, which offers strong privacy-utility trade-offs and ease-of-use in deployment; we adopt the SI-CIFG model architecture for efficient on-device training and compatibility with DP; and we use synthetic data from LLMs to improve pre-training. The dedication to privacy-preserving learning to improve small LMs has not only delivered substantial user benefits, but has also helped improve LLMs in mobile typing applications, bridged by synthetic data.
Synthetic data via public LLMs to boost private training
We describe our use of synthetic data for pre-training small LMs that are later post-trained with DP and FL in "Prompt Public Large Language Models to Synthesize Data for Private On-device Applications." We use powerful LLMs trained on publicly accessible data to synthesize high-quality and domain-specific data that resembles user typing data without accessing any private user data. This approach involves carefully designed prompts to instruct LLMs (1) to filter large public datasets to select text that is characteristic of mobile user interactions (sample prompt: “Is this topic likely discussed by people over their mobile phones?”); and (2) to transform selected text into a conversational format (prompt: “Convert this article to a conversation that you may message over your mobile phone.”); or (3) to directly generate conversation-like text based on specific and artificial scenarios (prompt: “Imagine you are a user messaging family on a mobile phone. Generate the chat.”)
The resulting synthetic data combines the public knowledge LLMs have learned from web data with developers’ domain-specific knowledge about mobile applications. Synthetic data do not expose user data that was not accessed during creation, and they can be inspected before being used in training. As evaluated in Gboard, pre-training on this synthetic data achieves a 22.8% relative improvement in NWP accuracy compared to pre-training on the baseline web-crawled data, and consistently achieves faster convergence and slightly higher NWP accuracy in post-training. Not too surprisingly, privacy-preserving post-training with DP-FL on user data significantly improves the model, and is still critical when launching these small LMs to improve the user typing experience.
Private training of small models on user data in a system currently supporting cross-device federated learning and central differential privacy with a trusted server. Trained models are deployed on mobile devices. Using synthetic data for public pre-training improves both the privacy-utility trade-off and computation efficiency.
Domain-adaptive synthetic data from LLMs and for LLMs
Synthetic data adapted to the domain of mobile applications is easy to use in any training pipeline. In addition to privately training small LMs, they are also useful for improving and deploying LLMs in this domain. In “Synthesizing and Adapting Error Correction Data for Mobile Large Language Model Applications”, we extend our synthetic typing data to improve LLMs’ error correction for mobile applications. Without accessing user data, we leverage Gemini to incorporate domain knowledge about common grammatical and typing errors via prompts such as “Here are some common grammatical errors: …Now apply these grammatical errors to the original sentences, and generate the ungrammatical sentences.” The prompted Gemini takes our synthetic data, which mimics user typing on mobile devices, to introduce error and create a dataset of corrupted–clean sentence pairs. We also prompt Gemini to further verify the correctness of the clean text (prompt: “Finally, correct the grammatical errors in the generated ungrammatical sentences. Do not modify the sentences except correcting the grammatical errors.”), which is particularly effective when we generalize the approach to languages beyond English. The synthetic datasets are used to transfer the error correction knowledge of the LLM to smaller, efficient, and focused models for mobile applications. These methods contribute to proofreading in the new ML Kit GenAI API.
Privacy-preserving buttress module to improve synthetic data
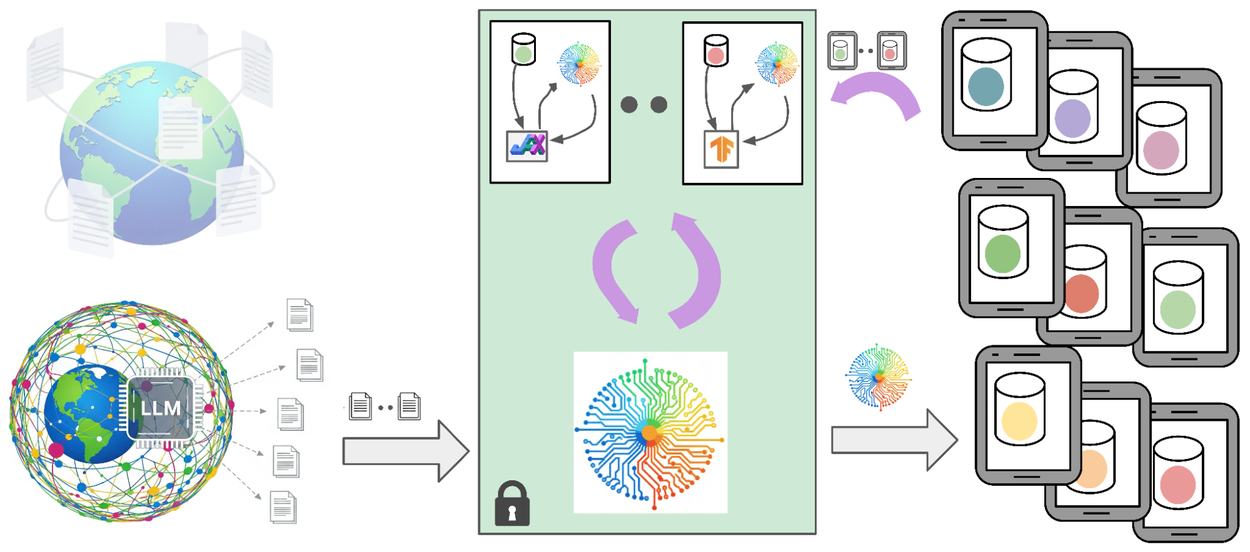
While prompting public LLMs is powerful, the domain of mobile user data has unique characteristics that are challenging to capture with only public data and developer knowledge, as indicated by studying both small and large pre-trained LMs in Gboard production. DP training on user data is a promising approach to further adapt the generator model to the private domain. However, training LLMs on mobile devices stresses current federated learning systems, which may have limited computation and communication resources.
To maintain strong data minimization and anonymization, we collect privacy-preserving signals from user data with DP-FL to guide synthetic data generation. Our early exploration uses the small LMs in Gboard to capture domain information. We call these small LMs fine-tuned with DP-FL buttress modules to reflect their role in supporting LLMs in generating representative synthetic data for various tasks. More specifically, we develop a reweighting model based on initial scores from small LMs, which learns to predict production performance of LLMs in mobile applications from the offline evaluation. Then we adapt the synthetic data by using the reweighting model: samples that the reweighting model identifies as more representative of the private domain receive higher weights. The reweighted synthetic dataset helps to better fine-tune the Gboard proofread LLM.

Advances in private training are used to train a small buttress module instead of directly improving task-specific (small) models. The buttress module is combined with public LLMs to generate privacy-preserving synthetic data. The synthetic data is a composable asset that bridges public knowledge and private information, which can be used in a standard training pipeline to improve small and large models.
Discussion and next steps
Applying synthetic data for both small and large models is proving effective for mobile applications. In addition to efficiently leveraging public knowledge in LLM generators, synthetic data potentially simplify the entire technical stack as the generated synthetic data can be used to train various models, including LLMs. Synthetic data can be inspected for debugging application development and audited for privacy protection. Throughout all our production usage, we also employ a defense-in-depth strategy and apply industry-level PII detection and model-level safeguards at multiple stages.
Moreover, leveraging privacy-preserving user signals via lightweight buttress modules is promising for further improving LLM capabilities in task-specific domains. Research rapidly advances for privacy-preserving synthetic data. With the development of new FL systems with trusted execution environments to improve capacity and new algorithms combining lightweight DP modules with DP fine-tuned generators [1, 2], the quality of privacy-preserving synthetic data from decentralized data can be significantly improved to serve various applications on mobile devices.
Acknowledgments
The authors specially thank Shanshan Wu for her technical contribution in generating synthetic data for Gboard applications. We thank Brendan McMahan and Daniel Ramage for the feedback on the blog post itself and the leadership support; Yuanbo Zhang and Daniel Ramage for inspiring and collaborating on the research; Zachary Garrett, Haicheng Sun, and Shumin Zhai for additional discussion and support. We thank Shaofeng Li for helping with the animated figures, and the teams at Google that helped with algorithm design, infrastructure implementation, and production maintenance.
Other posts of interest
-

July 29, 2025
Simulating large systems with Regression Language Models- Generative AI ·
- Natural Language Processing ·
- Open Source Models & Datasets ·
- Software Systems & Engineering
-

July 28, 2025
SensorLM: Learning the language of wearable sensors- Generative AI ·
- Health & Bioscience ·
- Machine Intelligence
-

July 22, 2025
LSM-2: Learning from incomplete wearable sensor data- Generative AI ·
- Health & Bioscience ·
- Machine Intelligence