
MLE-STAR: A state-of-the-art machine learning engineering agent
August 1, 2025
Jinsung Yoon, Research Scientist, and Jaehyun Nam, Student Researcher, Google Cloud
MLE-STAR is a state-of-the-art machine learning engineering agent capable of automating various machine learning tasks across diverse data modalities while achieving top performances.
Quick links
The rise of machine learning (ML) has fueled the development of high-performance applications across a wide array of real-world scenarios, from tabular classification to image denoising. However, crafting these models remains an arduous endeavor for machine learning engineers, demanding extensive iterative experimentation and data engineering. To streamline these demanding workflows, recent investigations have concentrated on leveraging large language models (LLMs) as machine learning engineering (MLE) agents. By capitalizing on their inherent coding and reasoning skills, these agents conceptualize ML tasks as code optimization challenges. They then explore potential code solutions, ultimately generating executable code (such as a Python script) based on a provided task description and datasets.

ML engineering agents are built to tackle diverse machine learning challenges by analyzing a task description and datasets that can span various modalities. Their ultimate goal is to pinpoint the best solution for the given problem.
Despite their promising initial strides, current MLE agents face several limitations that curtail their efficacy. First, their heavy reliance on pre-existing LLM knowledge often leads to a bias towards familiar and frequently used methods (e.g., the scikit-learn library for tabular data), overlooking potentially superior task-specific approaches. Furthermore, these agents typically employ an exploration strategy that modifies the entire code structure simultaneously in each iteration. This frequently causes agents to prematurely shift focus to other stages (e.g., model selection or hyperparameter tuning) because they lack the capacity for deep, iterative exploration within specific pipeline components, such as exhaustively experimenting with different feature engineering options.
In our recent paper, we introduce MLE-STAR, a novel ML engineering agent that integrates web search and targeted code block refinement. Unlike alternatives, MLE-STAR tackles ML challenges by first searching the web for proper models to get a solid foundation. It then carefully improves this foundation by testing which parts of the code are most important. MLE-STAR also utilizes a new method to blend several models together for even better results. This approach is very successful — it won medals in 63% of the Kaggle competitions in MLE-Bench-Lite, significantly outperforming the alternatives.
Introducing MLE-STAR
To generate initial solution code, MLE-STAR uses web search to retrieve relevant and potentially state-of-the-art approaches that could be effective for building a model.
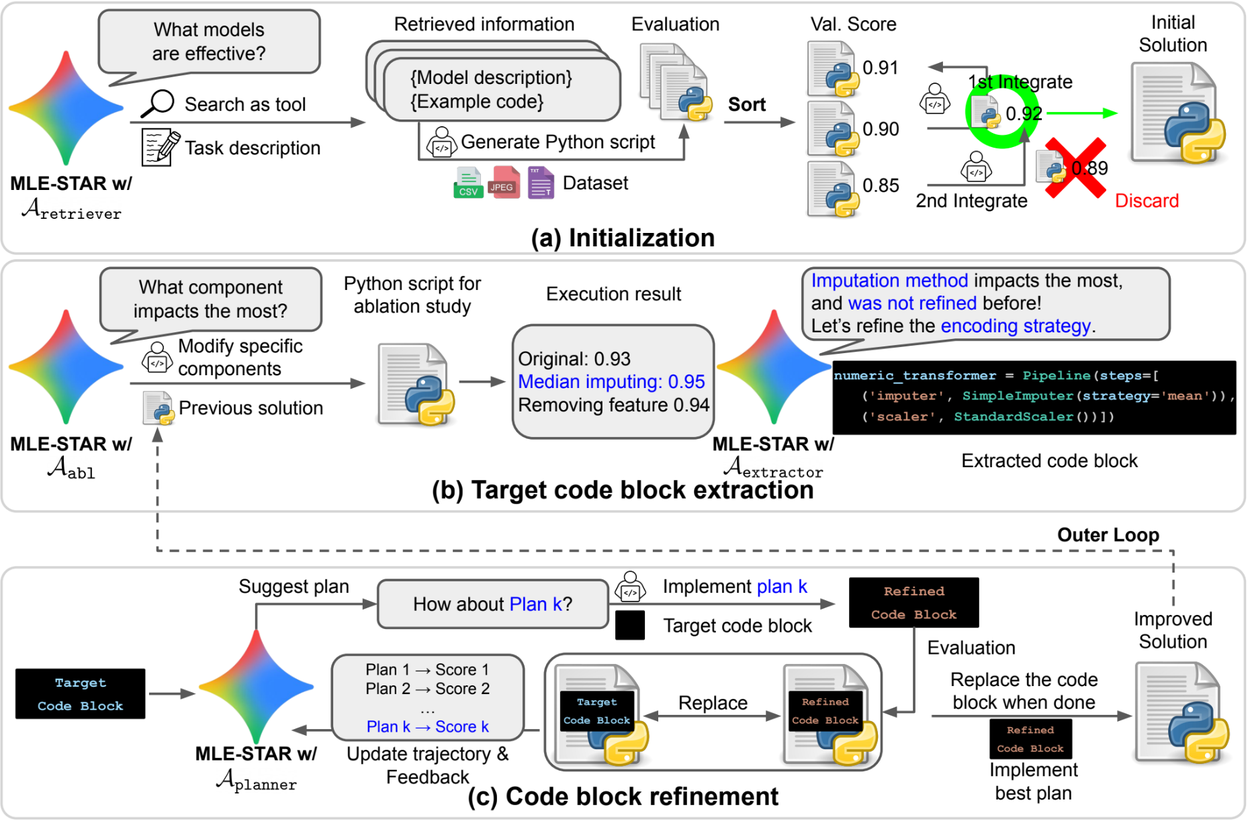
Overview. (a) MLE-STAR begins by using web search to find and incorporate task-specific models into an initial solution. (b) For each refinement step, it conducts an ablation study to pinpoint the code block with the most significant impact on performance. (c) The identified code block then undergoes iterative refinement based on LLM-suggested plans, which explore various strategies using feedback from prior experiments. This process of selecting and refining target code blocks repeats, where the improved solution from (c) becomes the starting point for the next refinement step in (b).
Additionally, we present a novel method for generating ensembles. MLE-STAR first proposes multiple candidate solutions. Then, instead of relying on a simple voting mechanism based on validation scores, MLE-STAR merges these candidates into a single, improved solution using an ensemble strategy proposed by the agent itself. This ensemble strategy is iteratively refined based on the performance of the preceding strategies.
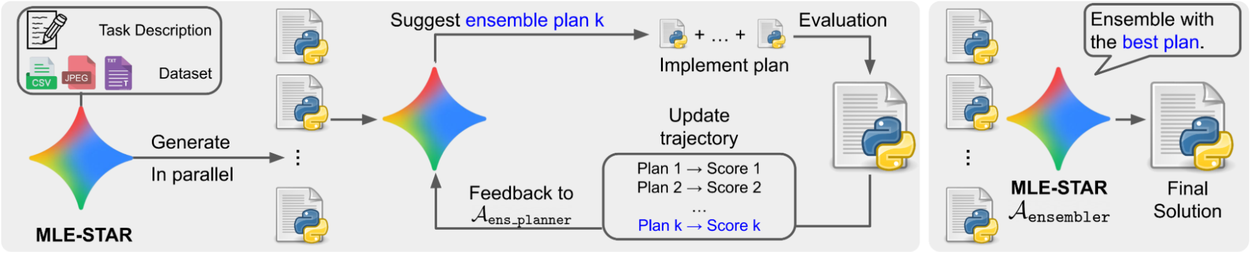
Ensembling Solutions: MLE-STAR refines its ensemble strategies over successive attempts, efficiently combining multiple parallel-generated solutions into a single, improved solution.
Last but not least, MLE-STAR incorporates three additional modules to enhance its robustness: (i) a debugging agent, (ii) a data leakage checker, and (iii) a data usage checker. For the debugging agent, if the execution of a Python script triggers an error, leading to a record (such as a traceback), MLE-STAR employs a debugging module to attempt correction. Regarding the data leakage checker, we've observed that LLM-generated Python scripts carry the risk of introducing data leakage, for instance, by improperly accessing information from a test dataset during training data preparation. To address this, we've introduced a checker agent that analyzes the solution script prior to its execution. As for the data usage checker, we've noticed that LLM-generated scripts sometimes neglect to use all provided data sources, focusing solely on simple formats like CSVs. To ensure the utilization of all relevant provided data, MLE-STAR includes a data usage checker agent.
Evaluations and results
To validate its effectiveness, we conducted comprehensive evaluations of MLE-STAR using the Kaggle competitions within MLE-Bench-Lite. Here, we utilized an additional agent that takes the task description and the final solution as input, and outputs the code that incorporates loading the test sample and creating a submission file.

Main results from MLE-Bench-Lite. Scores represent the average % of achievements in Kaggle competitions in MLE-Bench-Lite.
The experimental results presented in the figure above demonstrate that MLE-STAR, requiring only minimal human effort (e.g., defining initial prompts that are generalizable to any tasks), significantly outperforms previous alternatives, including those necessitating manual labor to collect strategies from Kaggle. Specifically, MLE-STAR achieves a substantial gain in any medal achievement, improving it from 25.8% to 63.6% when compared to the top-performing baseline.
In-depth analysis of MLE-STAR's gains
To understand the sources of MLE-STAR's performance gains, we conducted several analyses from various perspectives. Here, we examined (i) the types of ML models that MLE-STAR utilizes, (ii) how MLE-STAR can be extended with human intervention, and (iii) how the additional data leakage and usage checkers further improve MLE-STAR's performance.
- Model usage: Consider model usage by two MLE-agents. AIDE primarily employs ResNet for image classification. However, ResNet, released in 2015, is now considered outdated and can result in suboptimal performance. In contrast, MLE-STAR primarily utilizes more recent and competitive models like EfficientNet or ViT, leading to the observed performance gain.
- Human intervention: MLE-STAR readily adopts even more recent models with minimal human intervention. While MLE-STAR automatically constructs a model description using web search, a natural extension involves leveraging human expertise for this construction. By manually adding a model description for RealMLP, MLE-STAR successfully integrates its training code into the framework, a model not previously retrieved.
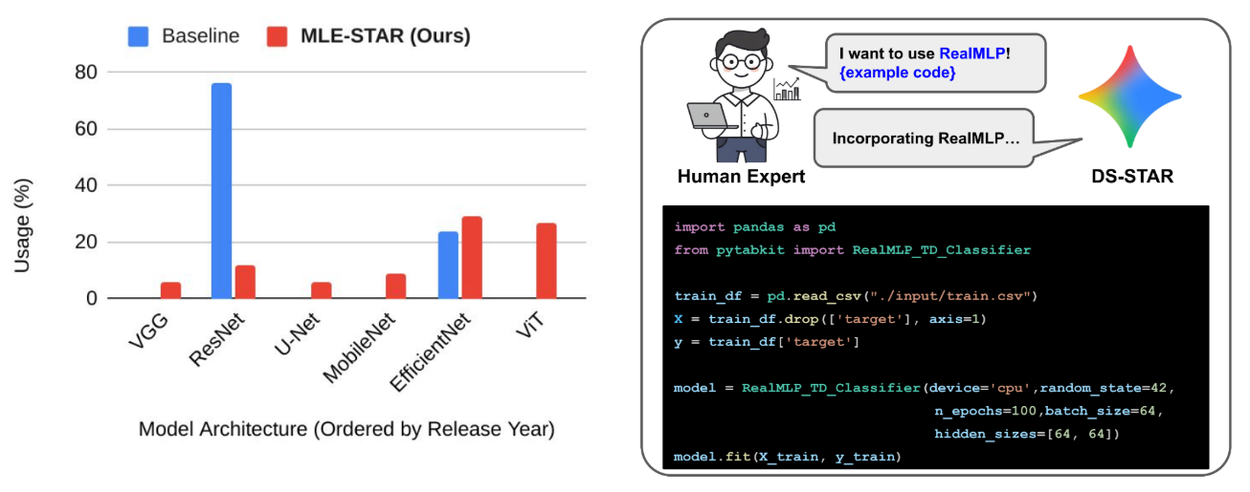
Left: Model usage (%) in image classification competitions. Right: Demonstrating human intervention: MLE-STAR integrates a model's training code based on a manual model description.
- LLM misbehavior and corrections: We observed that while the code generated by the LLM executed correctly, its content was sometimes unrealistic, exhibiting hallucination. For example, the figure below (left) illustrates an impractical approach where test data is pre-processed using its own statistics. Since test data must remain unseen, correction in the code is necessary, for which MLE-STAR employs a data leakage checker to identify such issues and refine the generated script if a problem is detected.
- We also observed that LLMs often generate scripts that overlook some of the provided data sources. To address this, MLE-STAR employs a data usage checker, which re-examines the task description to ensure that all given data is utilized. As shown in (right), this design enables MLE-STAR to incorporate previously neglected data.

Left: MLE-STAR's data leakage checker ensures appropriate preprocessing. Right: MLE-STAR's data usage checker identifies and incorporates previously unused information.
Conclusion
We proposed MLE-STAR, a novel machine learning engineering agent designed for diverse ML tasks. Our core idea is to utilize web search to retrieve effective models and then explore various strategies targeting specific ML pipeline components to improve the solution. The effectiveness of MLE-STAR is validated by winning medals in 63% (36% of which are gold medals) of the MLE-Bench-Lite Kaggle competitions.
By automating complex ML tasks, MLE-STAR could lower the barrier to entry for individuals and organizations seeking to leverage ML, potentially fostering innovation across various sectors. Furthermore, as state-of-the-art models are continually updated and improved, the performance of solutions generated by MLE-STAR is expected to automatically boost. This is because our framework leverages a search engine to retrieve effective models from the web to form its solutions. This inherent adaptability ensures that MLE-STAR continues to provide increasingly better solutions as the field of ML advances. Last but not least, developers and researchers can now accelerate their machine learning projects by using our newly released open-source codebase of MLE-STAR, built with the Agent Development Kit (ADK).
Acknowledgements
We gratefully acknowledge the contributions of Jiefeng Chen, Jinwoo Shin, Sercan O Arik, Raj Sinha, and Tomas Pfister.
-
Labels:
- Machine Intelligence
Quick links
Other posts of interest
-

July 28, 2025
SensorLM: Learning the language of wearable sensors- Generative AI ·
- Health & Bioscience ·
- Machine Intelligence
-

July 22, 2025
LSM-2: Learning from incomplete wearable sensor data- Generative AI ·
- Health & Bioscience ·
- Machine Intelligence
-

July 17, 2025
Measuring heart rate with consumer ultra-wideband radar- Hardware & Architecture ·
- Health & Bioscience ·
- Machine Intelligence